
分类: 谜のC语言
-
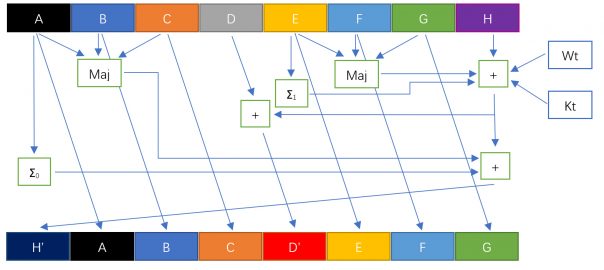
SHA-256 摘要算法 实现 及 优化
很久没有发文章了啊,咳咳,最近考试考的人心力交瘁。这两天由于需要(真的是自已的需要么?),做了做摘要算法方面的…
-

第三章:C++中的C
在使用C++编写程序的时候,我们会发现其中很多地方所使用的语句与C语言十分相似,其实从其命名可以看出来,C++…
-
第二章:对象的创建与使用 (2) (利用C++标准库创建对象)
在我们进行编程的时候,并不需要每次都从零开始构建一个程序,往往我们可以使用一些由其他人或者先前的工程师进行精心…
-
第二章:对象的创建与使用 (1) (基础知识与基本语法)
可以说,从这里开始算是C++的起步了,在接触对象之前,需要了解如何在一段代码当中创建以及使用一个对象。而在这之…
-
第一章:对象导言
最近听了别人的安利,对Think in C++这本书产生了一定的兴趣,刚开始读的时候,觉得甚是晦涩,因为它满篇…